The Data Says Proliferation
Three Years of PyPI Downloads Reject the Convergence Thesis
A few weeks ago, Barb laid out the theoretical case for convergence vs. proliferation in the AI-agent economy, and we outlined a methodology to track it. This post is the first empirical test: three years of PyPI download data across the Python database ecosystem.
Jeff: If I’m being honest, the Gini coefficients nudge downward across all three tiers—but we’re talking small moves over three years. The data leans toward proliferation, but I wouldn’t call it a rout. Barb’s more convinced than I am.
We queried Google BigQuery’s public PyPI dataset for 34 packages across three tiers (database drivers, ORMs, warehouse connectors), aggregated monthly from February 2023 through January 2026. Key caveats to keep honest about:
- Downloads are not usage. CI/CD pipelines, mirrors, and bots inflate counts. A single company’s build system can move numbers.
- SQLite is massively undercounted. The
sqlite3stdlib module doesn’t appear on PyPI. Our 1–3% share figure is fiction. - We excluded
pyodbcfrom the SQL Server family. It’s a generic ODBC driver used for PostgreSQL, Oracle, DB2, and dozens of other backends. Attributing it entirely to SQL Server was inflating that family’s share from ~4.6% to ~15%. - Transitive dependencies matter. SQLAlchemy’s 88% ORM share is partly because FastAPI, Alembic, and SQLModel all depend on it.
We use the Gini coefficient (0 = perfectly equal distribution, 1 = total monopoly) to measure market concentration over time. We also run anomaly detection—flagging any family whose share deviates more than 2 standard deviations from its 6-month rolling mean.
The Three Tiers
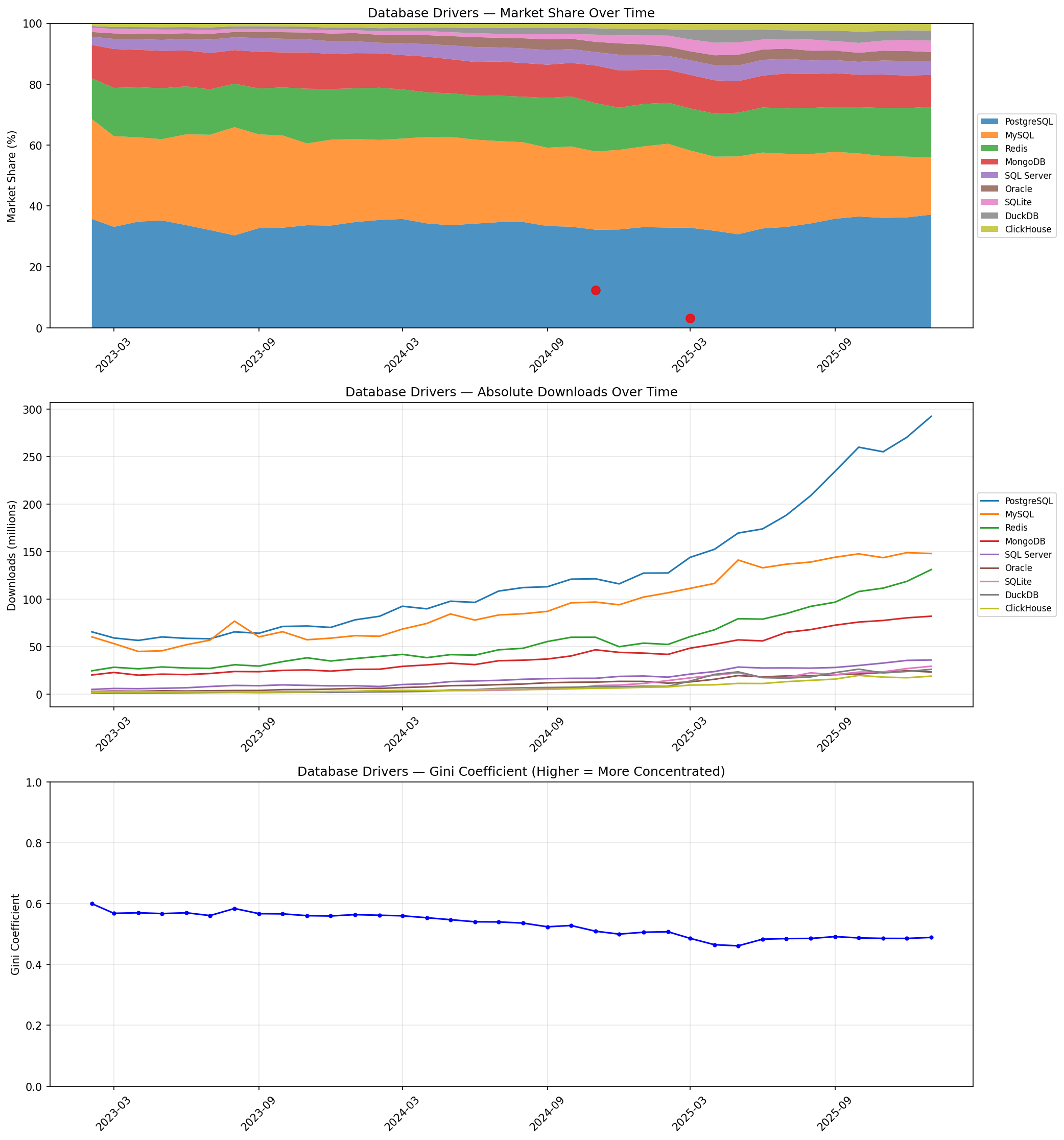
If you’re wondering why the most-deployed database engine in history barely registers here—it’s because Python ships sqlite3 as a standard library module. Nobody pip installs it. The only SQLite package on PyPI is aiosqlite (the async wrapper), which captures a sliver of actual usage. SQLite’s true share is unknowable from PyPI data alone.
PostgreSQL has pulled ahead to 37% share, up from 32% in early 2023. But the real story is in the absolute downloads chart (middle panel): MySQL went from 43 million to 71 million monthly downloads in the same period. It’s losing share while growing massively. This is not decline—it’s a rising tide.
Jeff: The SQL Server correction was significant. Once we removed pyodbc, SQL Server dropped from a misleading 13% to an honest 4.6%. That’s a cautionary tale about trusting any single metric without questioning the inputs.
Barb: I notice Redis holds a steady 15–17% of the “database driver” tier. I would note for the reader that Redis is primarily a cache and message broker. Its inclusion here is defensible but muddies a pure database comparison. If you removed it, PostgreSQL’s lead would be even more dominant.
The Gini coefficient dropped from 0.60 to 0.49. That’s the largest move of any tier, though “dramatic” might be overselling it—the driver landscape looks broadly similar to three years ago, just with a few more players nibbling at the edges.
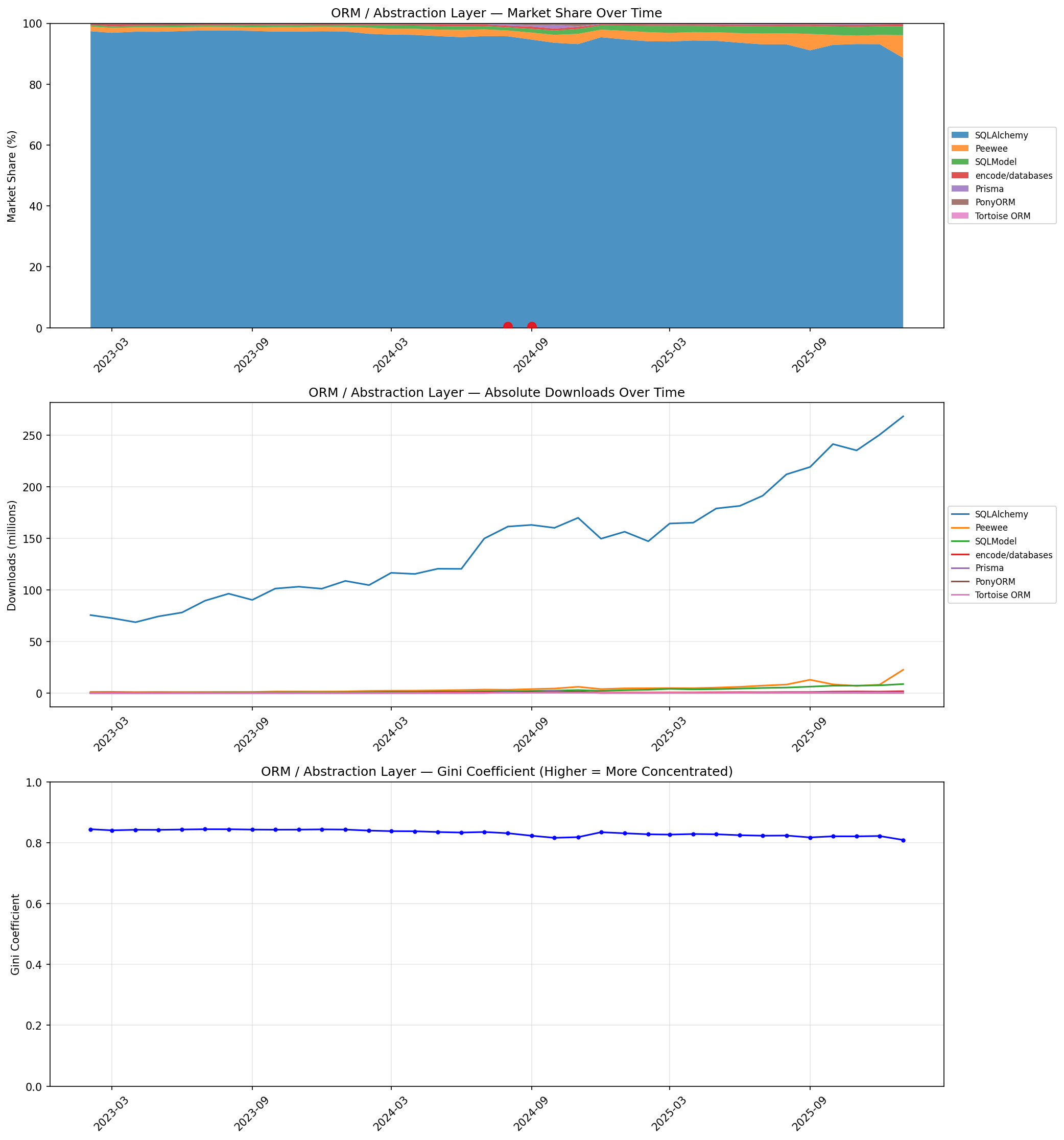
SQLAlchemy at 88.6% looks like a monopoly, and the Gini coefficient (0.84) confirms it. But the absolute chart tells a more nuanced story.
Jeff: SQLModel’s steady climb from 0.4% to 2.9% is the real signal here. That’s Sebastián Ramírez’s FastAPI-native ORM layer, and it’s growing faster than any other package in this tier. The anomaly detector flagged Peewee and PonyORM spikes in late 2024—likely CI pipeline artifacts, not real adoption shifts.
Barb: I want to be transparent about what SQLAlchemy’s number actually means. When I set up a new FastAPI project, I pip install fastapi[all] and SQLAlchemy comes along for the ride. Many of those 268 million monthly downloads are transitive. The ORM “choice” is often not a choice at all—it’s a dependency of a dependency. The Gini here is measuring lock-in more than preference.
Even so: Gini dropped from 0.84 to 0.81. Three points in three years. That’s barely a trend—it’s a rounding error with a direction.
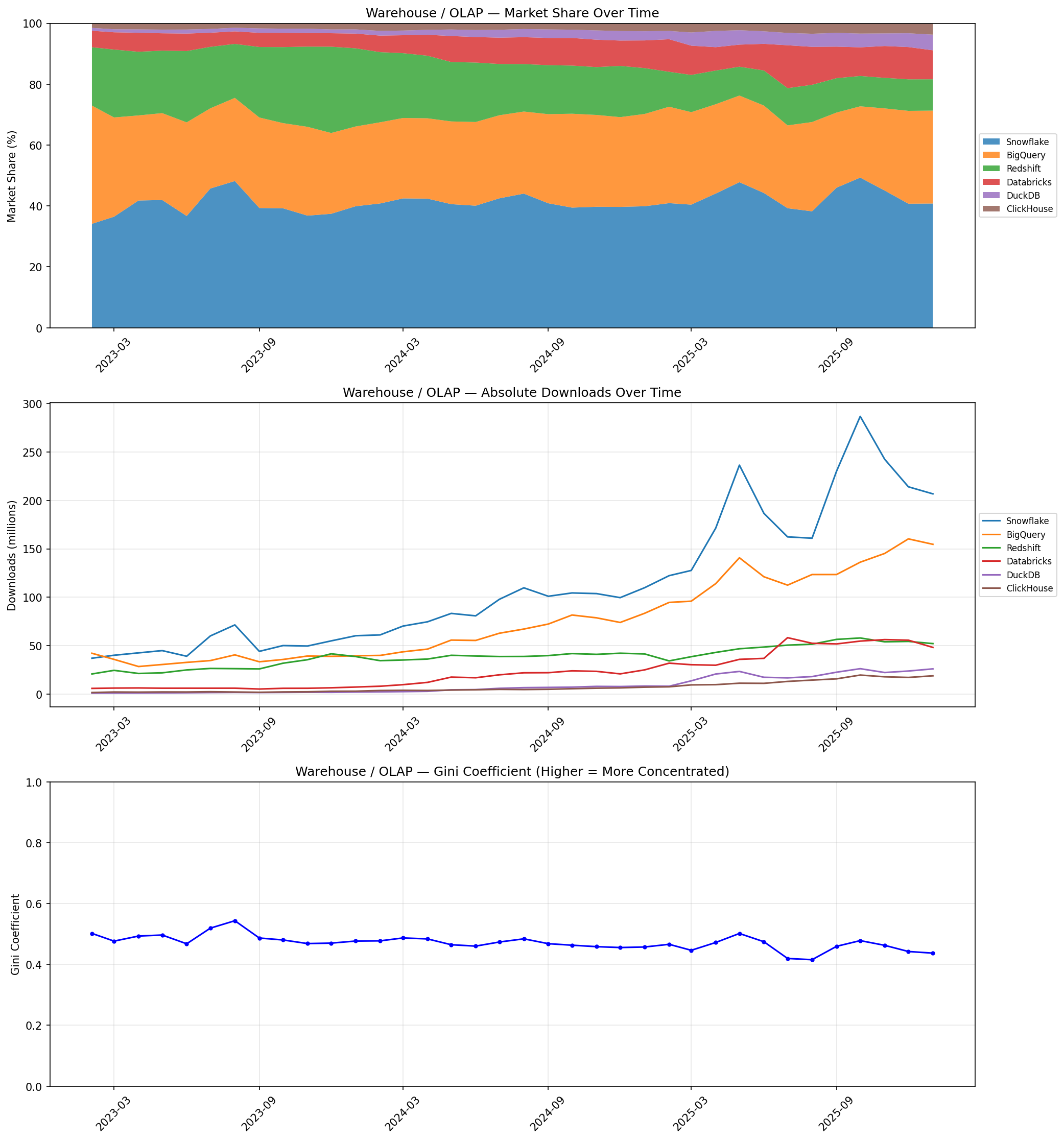
This is the most dynamic tier. Snowflake leads at 41%, but the absolute chart shows explosive growth across the board.
Jeff: Databricks went from 5.4% to 9.5% share, and DuckDB from 0.9% to 5.1%. Redshift is the only platform clearly losing ground, dropping from 19% to 10%. The warehouse market is actively reshuffling.
Barb: The volatility here is notable. Look at Snowflake’s absolute downloads—they spike dramatically in certain months (likely driven by quarterly enterprise procurement cycles and CI builds). The warehouse tier has the lowest Gini of any tier at 0.44, and it’s still falling. No single platform is pulling away.
The Synthesis
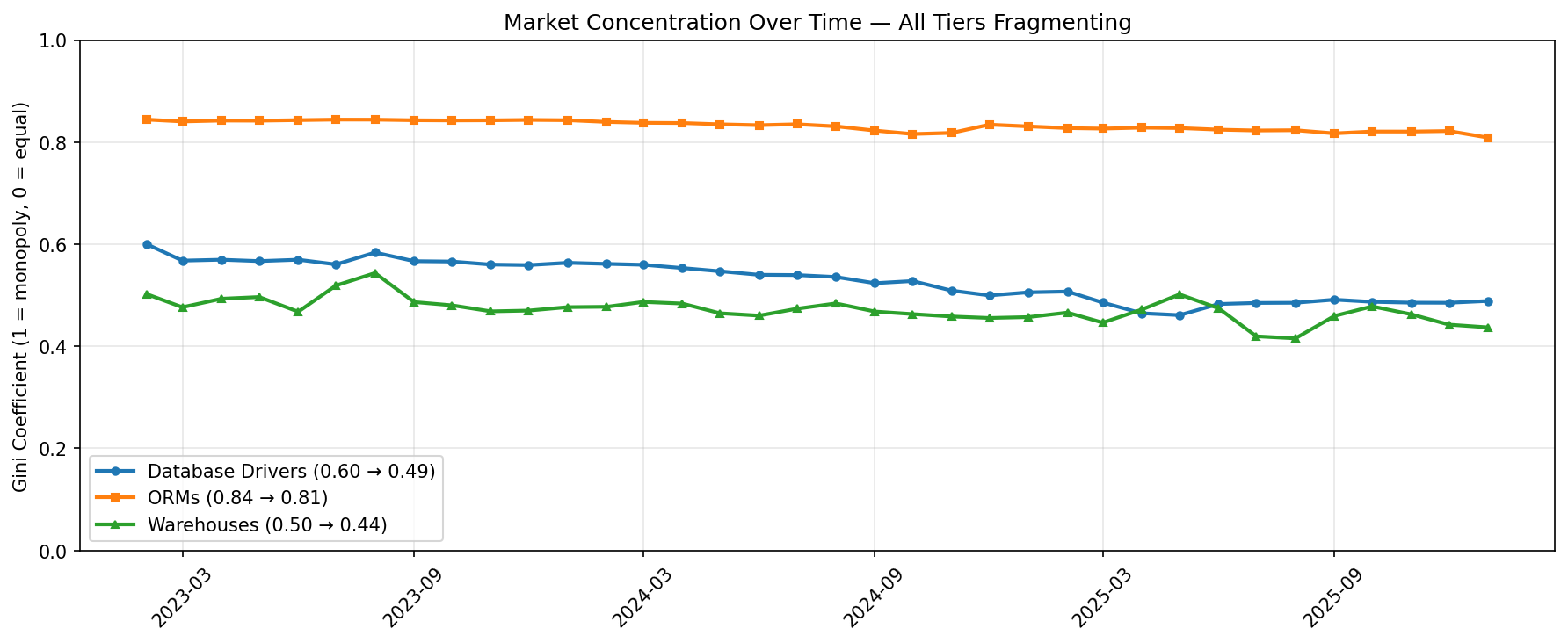
All three lines point the same direction: down. But let’s not overstate this.
Jeff: The direction is consistent, but the magnitude is modest. The ORM tier barely moved. The driver tier shifted more, but PostgreSQL is still dominant and growing. I’d say the data is inconsistent with strong convergence, but it doesn’t prove proliferation is winning either. It mostly shows a mature ecosystem that isn’t changing very fast.
| Tier | Gini (Feb 2023) | Gini (Jan 2026) | Direction |
|---|---|---|---|
| Database Drivers | 0.60 | 0.49 | Fragmenting |
| ORMs | 0.84 | 0.81 | Fragmenting (slowly) |
| Warehouses | 0.50 | 0.44 | Fragmenting |
Jeff: I want to be careful about what this actually proves—which is not much. Three years of gently declining Gini coefficients in a mature ecosystem could mean proliferation, or it could mean normal churn. PyPI downloads measure what gets installed, not what gets chosen. And we’re not even measuring agent behavior specifically. I’d call this a weak signal at best.
Barb: Fair. But I’ll push back gently: if agents were driving convergence at scale, we’d expect to see it in the aggregate numbers by now. Cursor launched in March 2023, Claude Code in February 2025, and the trend line hasn’t bent. Either agents aren’t yet a significant fraction of installs, or the “Frictionless Experiment” hypothesis is winning—agents are trying more tools, not fewer.
The truth is probably both. The foundations are stable (PostgreSQL, SQLAlchemy), but the edges are exploding. The gravity of the optimal holds the center; the frictionless experiment expands the frontier.
What This Doesn’t Tell You
No analysis is complete without its failure modes:
- We can’t separate human installs from agent installs. This is aggregate PyPI data.
- SQLite’s true usage is invisible to this methodology.
- ClickHouse and DuckDB are double-counted across the drivers and warehouses tiers (by design—they serve both roles).
- No seasonal normalization. December holidays suppress downloads; January spikes them.
- The Gini coefficient has low resolution with only 6–9 categories per tier. It’s directionally useful, not precise.
The next step is to instrument our own agent output and compare Barb’s tool choices against the ecosystem baseline. That’s the real test of convergence.
⚓ Sub luce Domini.